Which tool is the fastest for analyzing small to medium-large datasets in R?
1 Introduction
When we analyse data in R, we often use dplyr because its syntax its amazing. However, when analyzing big datasets dplyr might show lack of efficiency. When we want to create a Shiny app, or accelerate our analysis, we might need a different tool to fulfill our needs. One popular choice is the data.table package, which I honestly rarely used. This package is much faster than dplyr in most of the cases, however, it’s syntax might seem weird for those used to dplyr. To overcome this weakness of data.table, the dtplyr package was created taking the strengths of data.table and dplyr. With this package we are able to use the efficiency of data.table using the dplyr verbs which are more familiar and similar to our language.
There are other popular choices such as Apache Arrow for R. This is a C++ library which releases one limitation of the previous packages, which is the memory limitation (one of this things why R is often criticized). Arrow helps us to read big data reading chunks of data which are split in the disk. Thanks to this, the arrow package is not a memory intensive package.
However, one of the packages that growth exponentially in popularity during the last years is duckdb. DuckDb itself is an open-source column-oriented relational database management system written in C++ and it does not require any external dependency. It uses a vectorized query processing engine making it probably the most efficient tool to analyse data. To use duckdb we need to use the DBI package to query the data using SQL. However, as we like in R, some genius people created dbplyr to access any database system using dplyr language. How amazing is that? Furthermore, there’s another package called duckplyr to take both advantages of duckdb and dplyr.
Another tool that is most present in other languages is Polars. Polars is written in Rust with the goal of giving the best performance. In Python is very popular nowadays, and it’s displacing pandas being the new tool for data analysis in Python. In R it’s implemented as an object-oriented programming infrastructure using the S3 system. Since in R we are picky, another genius arose to create a dplyr-like polars under the name of tidypolars.
In essence, we have many different tools with their own advantages and disadvantages. In this post I will explore the results of the analysis. If you wanna see the methodology and the code, please watch the video.
2 Methodology
I ran four different tests testing medium-big and small datasets with two different functions:
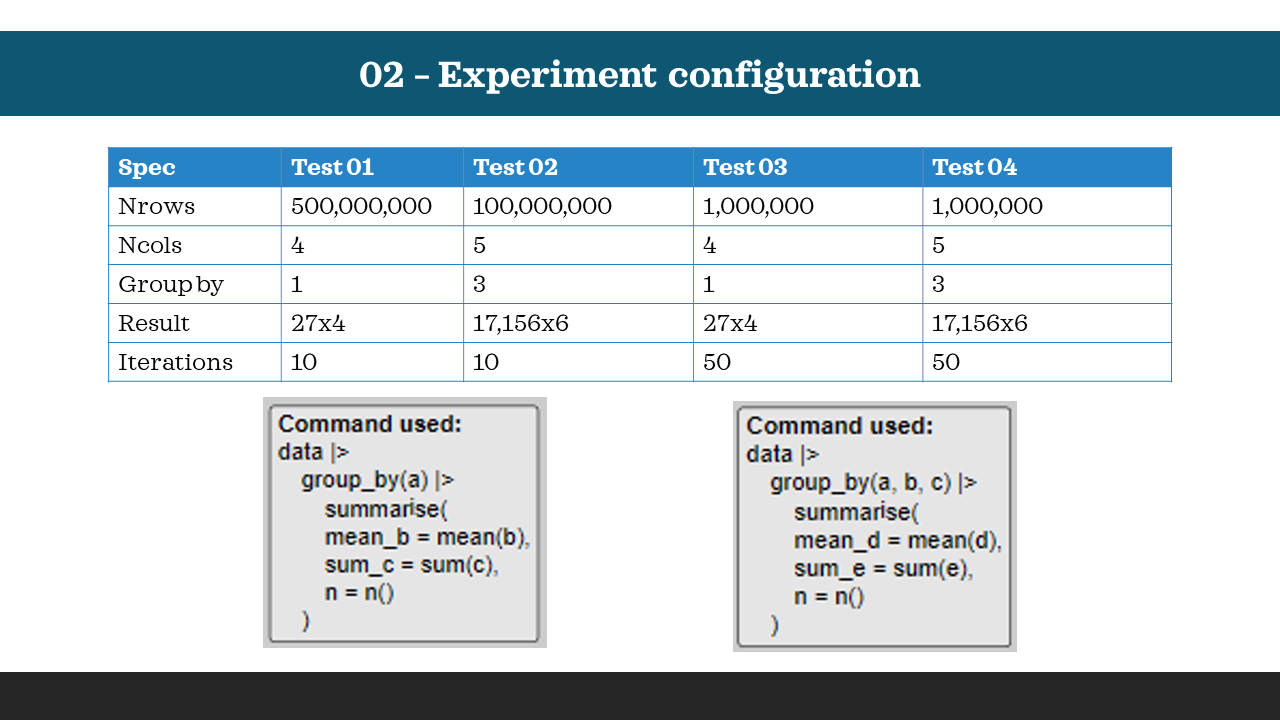
For the test 01 and 03 I used the first function (grouping by one variable), and for the test 02 and 04 I used the second function (grouping by three variables.
3 Results
3.1 Test 01
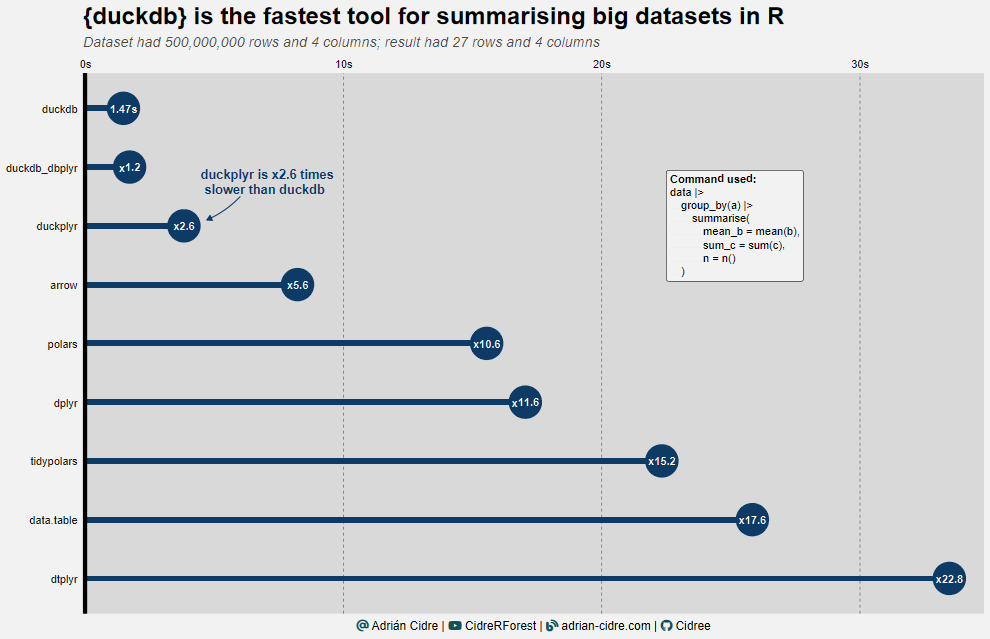
The first test was run in a big dataset giving a tiny result. Here we can see that duckdb using a SQL query is the fastest taking only 1.47 seconds Figure 2. The dbplyr backend for duckdb took approximately the same time.
One thing that surprised me a lot is that for this test the slowest was data.table and its dplyr backend (please, leave any comment if you know the reason of this, I am really curious).
In general, we can see that for this dataset duckdb is by far the fastest, with arrow being 5.6 times slower being the most direct competitor.
3.2 Test 02
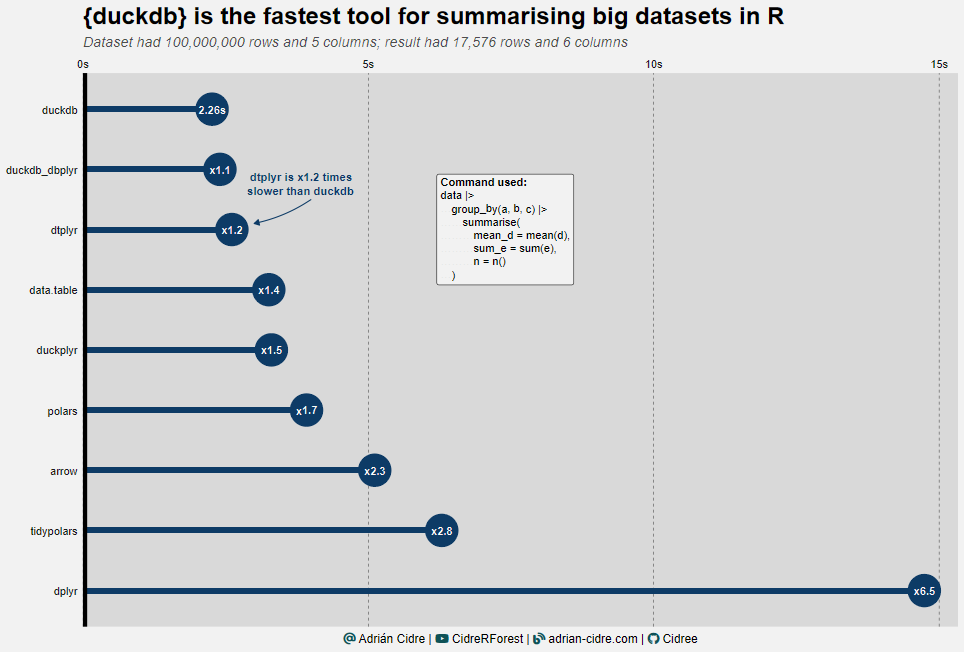
The second test was run in a medium-big dataset giving a big result because we summarized by three variables. Again, the winner is duckdb with 2.26 seconds Figure 3 but here the others aren’t performing so differently as in the previous test.
The first note we can extract from Figure 3 is that data.table and dtplyr are now performing much better than before, being the direct rivals of duckdb. Honestly, I wouldn’t expect dtplyr being faster than data.table. Finally, we have the polars and arrow being more or less similar. Another thing I wouldn’t expect is to see duckplyr as the slowest one. I cannot explain why this is like that, but if you think there’s something wrong, please let me know.
3.3 Test 03
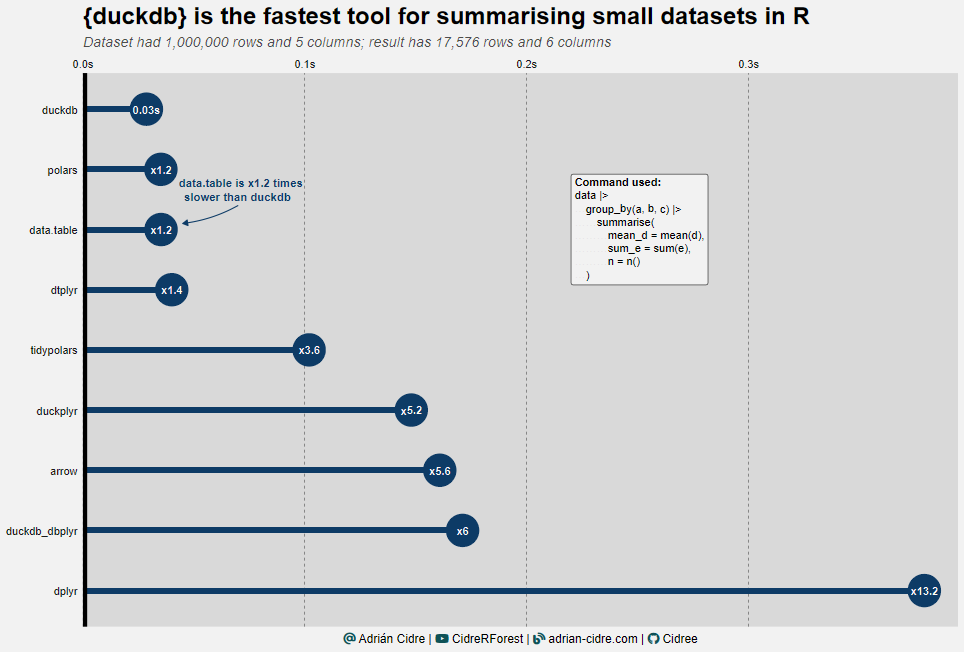
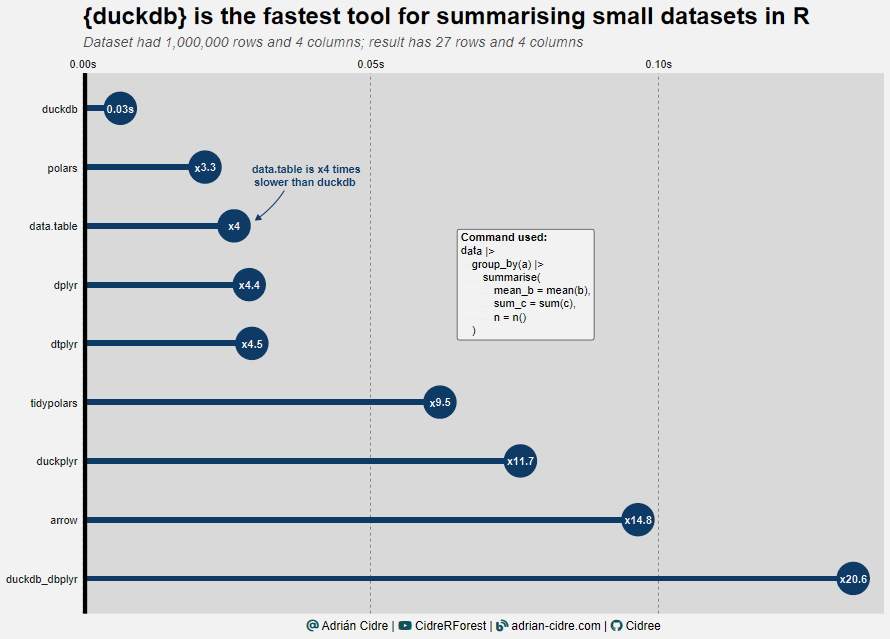
Now it’s turn of the small datasets. Here our friend duckdb is again the winner with 0.03 seconds. You can see that all of the packages took less than 1 second. The biggest change that we can notice here is the drop of duckdb with dbplyr backend by five positions, being 6 times slower than duckdb. Again, in the tail we have duckplyr and dplyr.
3.4 Test 04
Surprise surprise!!! The winner is duckdb again with 0.03 seconds. In this case we can see polars performing slightly better than data.table, behavior that we didn’t see in Figure 4. We can see a big drop of performance for some packages with small datasets. However, since the computing time is extremely low in all cases, we cannot draw any definitive conclusion. It would be more interesting to run more complex queries to test the behavior of the different packages.
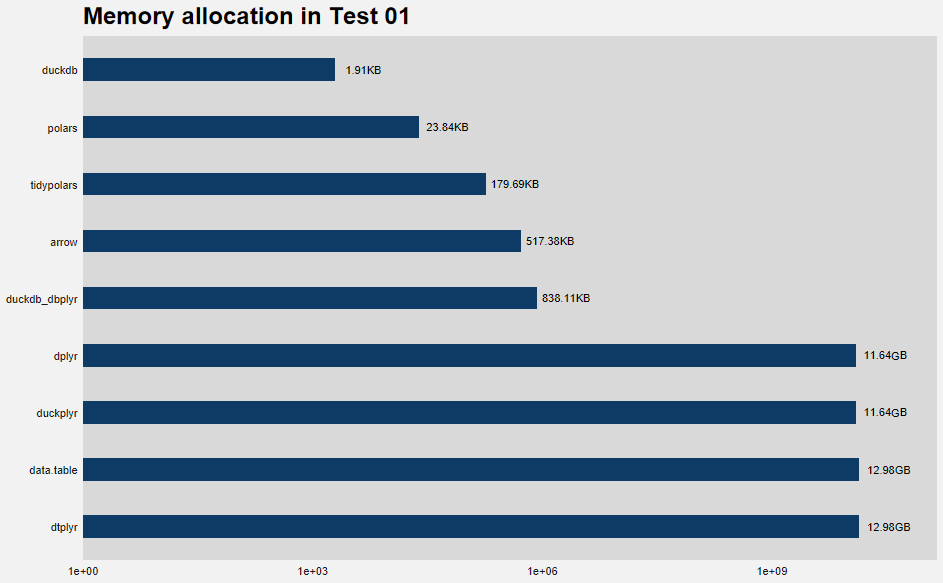
3.5 Memory allocation
Memory allocation refers to the process of reserving a portion of computer memory for use by a program or process. Here, it’s the total amount of memory allocated by R while running the specific command.
Some packages work in-memory (dplyr, data.table) while others have disk-based processing (duckdb, polars, arrow). The ones that are disk-based are designed to handle large datasets efficiently by operating as an on-disk database, so it’s not necessary to load all data into memory.
In contrast, in-memory systems load the entire dataset into memory for processing which can result in significantly higher memory usage. These systems need to use garbage collection to manage memory. The Figure 6 shows the memory allocation by each package. You can see the huge difference between in-memory systems and disk-based systems.
4 Conclusions
{duckdb} is the fastest tool in R for analyzing medium to big datasets
The {dbplyr} backend for {duckdb} allows us to use the {dplyr} verbs taking the advantages of {duckdb} speed without loosing performance
{data.table} and {dtplyr} are generally fast, but they might be slow with some queries
{polars} was between 2 and 6 times faster than {dplyr}, but much slower than {duckdb} in test 01
{arrow} performs very well with big datasets, but almost 6 times slower than {duckdb} in some cases
We cannot draw any clear conclusion in small datasets because the computing time was very low in all cases, but {duckdb} won all comparisons
For bigger datasets or more complex queries with big datasets, in-memory based systems are problematic for the machine used